Let’s say you need to integrate data on a weekly basis between two applications. You used to do that manually, and it takes you one hour every week. It is not a big deal, but you could use that time for more important stuff. Since you have a small company, you can’t allow a huge budget to go into making this, or into licences and subscriptions.
Let’s build in 5 minutes a data pipeline, without complicated technologies.
You need a machine somewhere and a shell. That’s it. What is nice is that you very probably already have one somewhere, maybe the same server where the data needs to be integrated.
Theoretically, it is better to have dedicated environments for the data engineering layer. But considering the scenario and the size of the company, you’re not at that stage yet, so it is fine to proceed as such.
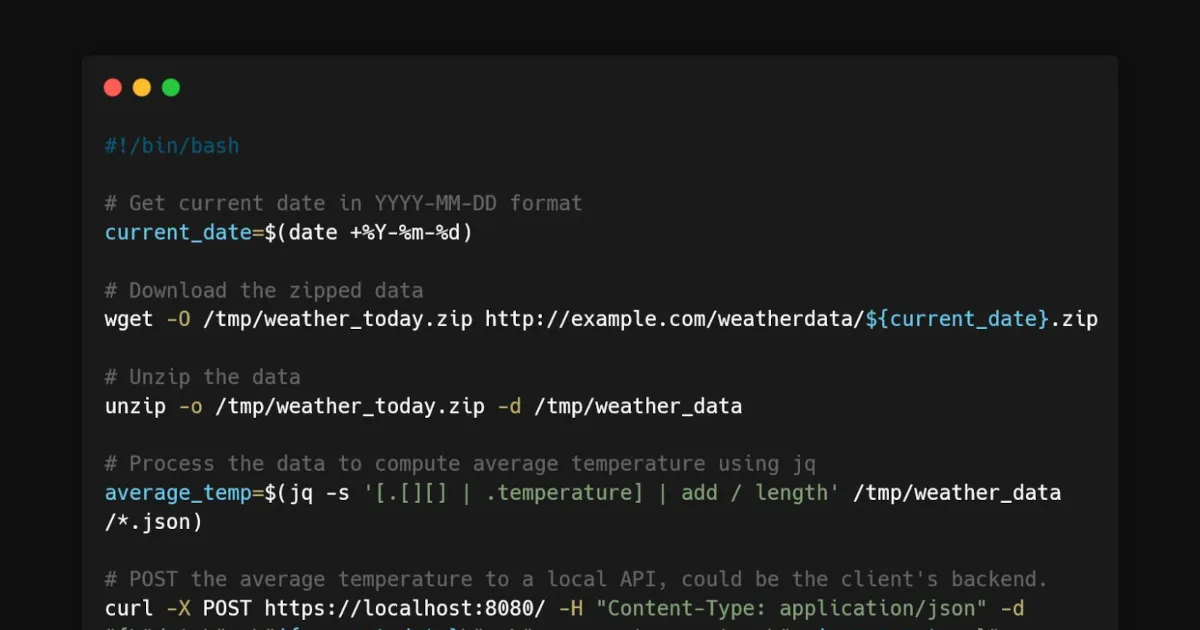
In the code block below, is a bash script that is orchestrated by a crontab. It runs every week on Monday at 6am, pulls data from a Weather API, unzip it, aggregate all the data to compute the average temperature, and push that result in another API as a HTTP POST call. A fictitious yet very standard ETL where you pull data from a source, perform a little transformation on it and push the result somewhere else.
#!/bin/bash
# Get current date in YYYY-MM-DD format
current_date=$(date +%Y-%m-%d)
# Download the zipped data
wget -O /tmp/weather_today.zip http://example.com/weatherdata/${current_date}.zip
# Unzip the data
unzip -o /tmp/weather_today.zip -d /tmp/weather_data
# Process the data to compute average temperature using jq
average_temp=$(jq -s '[.[][] | .temperature] | add / length' /tmp/weather_data/*.json)
# POST the average temperature to a local API, could be the client's backend.
curl -X POST https://localhost:8080/ -H "Content-Type: application/json" -d "{\"date\": \"${current_date}\", \"average_temperature\": $average_temp}"
# Clean up
rm /tmp/weather_today.zip
rm -r /tmp/weather_data
####### Record to include in the crontab configuration #######
# Every week on Monday at 6 AM - Download, unzip, process, and store weather data
0 6 * * MON /path/to/process_weather_data.shA few lines of bash and it’s done. All of these tools are available on any Linux-based server.
Document
Last but not least, don’t forget to document the process. Note where it’s running, what machine it’s on, and who’s in charge of keeping it going. Make it easy for anyone to pick up if needed.
Wrap-up
How many of these tiny pipelines are bogged down in overbuilt environments, draining budgets for barely any real added value? How much time are we wasting with this obsession over big setups for small jobs?
So, next time you’re thinking about spinning up some monster stack for a pipeline, stop. Think about what it actually needs. Maybe it’s just a shell, a script, and a periodic run time. Simple as that.
And if you need help with the strategy, contact me.