GPT-5.5 feels like one of those moments where you look at a tool you already use every day and realize the ground has shifted just enough to notice. The tool is still there, the workflow still makes sense, the excitement is still real, but something in the economics has become too visible to ignore. You look at the pricing page, you look at your own usage, and you start wondering whether the way you use these models should evolve along with the models themselves.
I find that exciting rather than depressing. We are not only watching models get better; we are watching them become real professional tools, with real trade-offs, real prices, and real decisions attached to them. That makes the whole thing more interesting than the old habit of picking the best model, sending everything to it, and hoping the bill stays somewhere in the background.
The price signal
The thing that made me stop for a second was simple: GPT-5.5 costs twice as much as GPT-5.4 on OpenAI’s pricing page. This is not the usual small premium for the newest shiny thing, or a slight increase that disappears in the noise of normal usage. It is twice as much per token, which is enough of a jump that even if you are enthusiastic about the model, you have to take the price seriously.
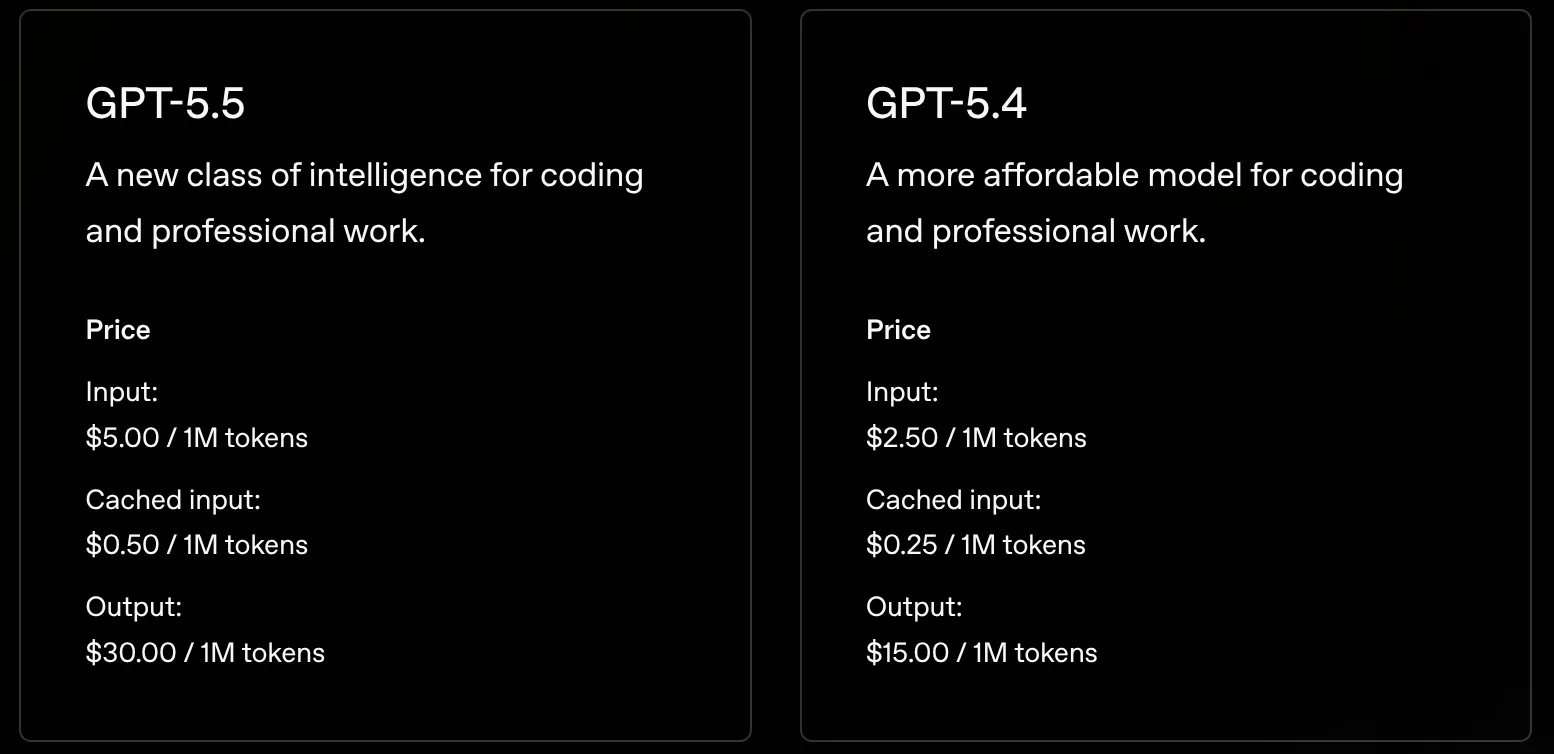
Once you see that, the natural question appears by itself: is it twice as good? The question is unfair if you take it literally, because models do not improve in neat multiples and nobody should expect a model that costs twice as much to fix twice as many bugs, write twice as much useful code, or make every agent session twice as productive. But the question is still useful because it nudges us away from treating “best model” as a complete answer.
For a while, that was more or less my default behavior. A new best model appeared, I switched to it, and I moved on. If it was better, why not use it? The cost was not invisible, but it was abstract enough to ignore most of the time, right up until the usage limit that felt far away suddenly became very real. GPT-5.5 makes that habit worth questioning, not because the model is uninteresting, but because the trade-off has become much clearer.
Better does not mean twice as good
The benchmarks improve, the reasoning may be better, the coding may be sharper, and the model may get stuck less often or recover better when it does. I am happy to believe that GPT-5.5 is meaningfully better than GPT-5.4 in plenty of situations, because better tools are good news when they help you stay in flow instead of wrestling with the machine.
At the same time, the visible benchmark gains do not double just because the token price doubles. We are paying twice as much per token, but we are not seeing twice the public benchmark performance, and that gap between price and visible improvement is where the interesting question lives.
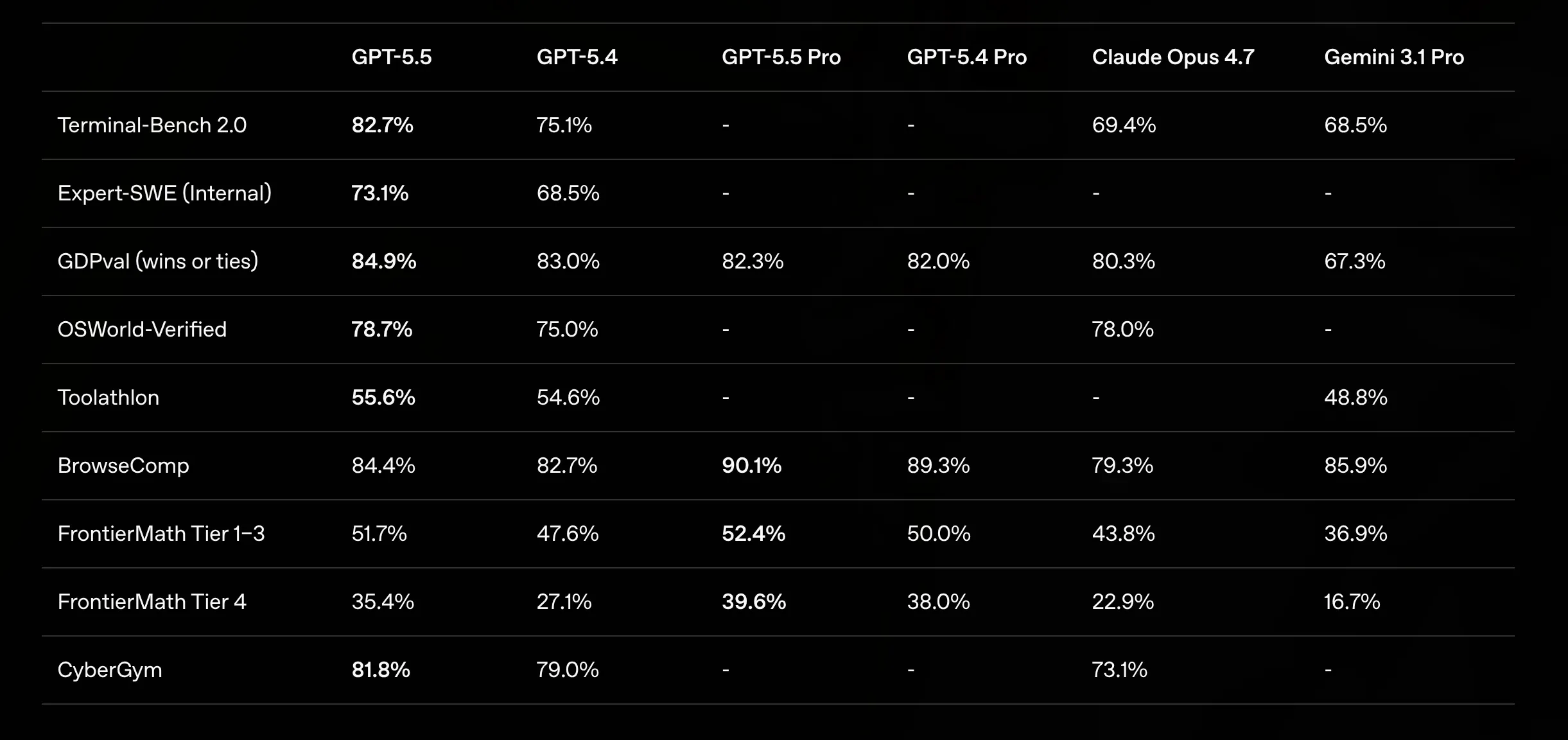
This does not mean GPT-5.5 is overpriced, and I do not think that is the right conclusion anyway. The cost of using a model is not just the posted input and output price, because the real cost depends on how many tokens it uses, how often it gets the answer right on the first attempt, how many retries it avoids, how much time it saves, and how much better the final result is.
A more expensive model can still be cheaper in practice if it gets you to the right place faster. Anyone who has spent an hour fighting a bad answer from a cheaper model knows that sometimes the premium model is not a luxury at all, but simply the shortest path out of the swamp.
But once the price jump becomes this visible, it becomes worth asking a more precise question: use the best model for what?
Efficiency in theory, cost in practice
OpenAI says GPT-5.5 can be more efficient, including using fewer tokens on some Codex tasks, and I have no reason to dismiss that. In controlled workflows, with specific task sets, better models can need fewer attempts and waste less context, which can offset part of the higher price when the model reaches the right answer with less wandering.
In my own usage, though, I did not feel a clear drop in token consumption compared with previous models. This is not a benchmark, and I am not pretending it is one; it is just a field note from actually using the thing. A model can be more efficient in a controlled setting and still feel expensive inside a real agentic coding workflow, which is part of what makes this moment interesting. We are learning how these tools behave outside the demo, outside the benchmark, inside the messy loop of everyday development.
Paying for a work loop
During one coding session with GPT-5.5 through an AI agent, I burned through around 500,000 tokens in less than two hours and quickly hit my usage limits. This was not some grand experiment where I asked the model to rewrite half the internet; it was the kind of session that now feels normal, where the agent inspects files, reasons about the structure, makes edits, reads outputs, adjusts, validates, and continues.
That loop is exactly why AI coding agents are useful, and it is also why they can become expensive so quickly. With agents, we are no longer paying for a single answer, but for a work loop where every file read, every plan, every patch, every failed attempt, every validation step, every follow-up question, and every chunk of context that gets carried forward becomes part of the cost.
The model is not sitting in a chat box waiting to answer one carefully phrased prompt. It is walking through a codebase with a flashlight, checking corners, opening drawers, trying things, correcting itself, and sometimes wandering into rooms it did not need to enter, which is both part of the charm of these tools and part of the bill.
This is why price-per-token can feel misleadingly small. A token is tiny and a cent is tiny, but agent loops are not tiny once they start compounding over file reads, edits, retries, and validation steps. A model that is twice as expensive per token does not feel twice as expensive when you ask one short question; it starts to feel different when it is allowed to run, explore, edit, recover, and continue for hours.
Expensive is not the same as overpriced
None of this means the model is a bad deal. If GPT-5.5 saves a senior developer several hours on a hard bug, the cost may be trivial, and if it helps avoid a broken migration, a bad architecture choice, or a production incident, it may be a bargain. Expensive is not the same as not worth it.
The fun part of this shift is that we are moving from “AI as a magical text box” to “AI as a set of professional tools with different prices and different strengths”. That is a healthier place to be because it means we get to develop taste, compare tools properly, build workflows, and ask when we want the absolute best model versus when another model is more than good enough.
Premium tools need premium tasks
There is a simple intuition here: you do not need the best surgeon in the hospital to put a bandage on your finger, you do not call your best architect to move a chair, and you do not rent a crane to carry a box. Not because surgeons, architects, or cranes are overrated, but because capability should match the job.
AI models are moving into the same world. Frontier models are becoming premium tools for work where the premium matters. Understanding a complex system, planning a risky refactor, diagnosing a subtle bug, reviewing an important design decision, reasoning through ambiguous trade-offs: these are the moments where I am still very happy to bring in the best model available.
But renaming variables, applying an obvious checklist, generating boilerplate, writing simple tests, or editing documentation after the decision is already made probably does not require the Ferrari. Sometimes the bicycle is fine, and sometimes the bicycle is better precisely because it is cheap, fast, and does exactly what you need.
Why this is happening now
It is not hard to understand why this is happening once you look at the numbers, and the numbers should not be read as “OpenAI is already a normal profitable software company”. Reuters reported that OpenAI generated about $4.3 billion in revenue in the first half of 2025, already more than the company had generated in all of 2024, but also burned $2.5 billion over the same period. The same report said research and development cost $6.7 billion in just those six months, which is a nice reminder that frontier AI is not a normal SaaS business where the main expense is a few servers and some engineers.
The full-year numbers tell the same story at a larger scale. CNBC reported that OpenAI generated $13.1 billion in revenue in 2025, beating its own $10 billion target, but still burned through $8 billion during the year. Reuters also reported that OpenAI is targeting roughly $600 billion in total compute spend through 2030. That is the shape of a company with huge demand and huge revenue, but also huge losses, huge capital needs, and a very strong incentive to make the economics work.
So when OpenAI prices a frontier model aggressively, I do not read it as a random cash grab. I read it as part of the basic financial reality of the business: this company is investing like hell, raising and arranging enormous amounts of capital and infrastructure, and trying to turn a technological lead into a balance sheet that can eventually support the machine it is building.
I do not find it shocking that the best models are becoming more expensive. In a way, it is probably part of the maturation of the market, because the free lunch feeling was never going to last forever. The interesting question is what developers do next.
What changes for developers
GPT-5.5 does not make me want to stop using frontier models; quite the opposite, it makes me want to enjoy them more deliberately. I still want the best model when the task is hard, uncertain, or risky, when I need judgment rather than execution, and when the cost of a wrong answer is higher than the cost of the tokens.
What I am less excited about is burning the most expensive model on every step of every workflow simply because it is available. That was comfortable, and I understand the habit because I had it too, but now the pricing invites a better habit: split the work, use the frontier model where the thinking is hard, use something cheaper where the path is clear, and bring the frontier model back when the task becomes uncertain again.
This feels less like a restriction and more like a new craft. Developers are going to become better at routing work between models, learning which models are good enough for which jobs, and developing little workflows, preferences, tricks, and rules of thumb in the same way we learned when to reach for a database, a cache, a queue, a script, or a spreadsheet.
I wrote more about that habit in The Developer-Router: Right Model, Right Time, because I think this is where the practical change really starts for developers.
That is what I find enjoyable about this moment. The model got better and the model got more expensive, but the real story is that our usage patterns now have to get more sophisticated too.
A more interesting default
I am not going to stop using frontier models, because I like them too much for that, but I am going to stop using them for everything.
GPT-5.5 is not the end of frontier models for developers. It is the beginning of using them with more taste.